
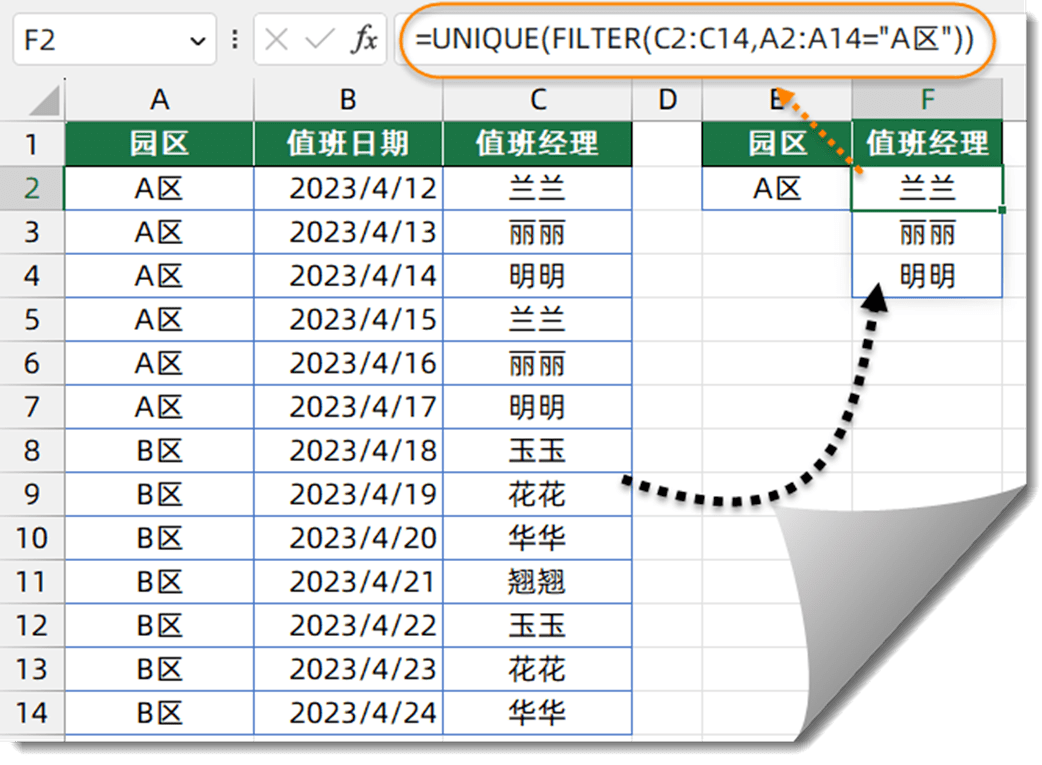
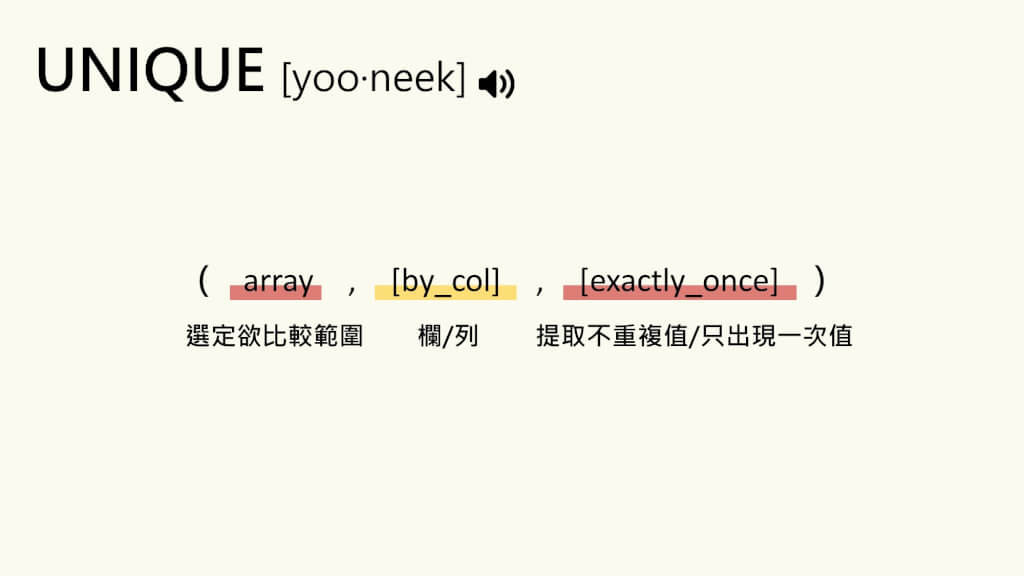
Unique函数的使用方法,,Unique函数是一个用于去除数组中重复项的函数。它接受一个数组作为参数,并返回一个新的数组,其中重复项已被去除。,,使用Unique函数时,需要注意以下几点:,,1. 去除重复项的操作是不可逆的,因此在调用Unique函数之前,请确保您已经备份了原始数组。,2. Unique函数只适用于数组类型的数据。如果您尝试在列表、字符串或其他数据类型上使用它,将会出现错误。,3. 在处理大型数组时,Unique函数可能需要一些时间来去除重复项。请耐心等待,或者考虑使用其他方法来实现相同的功能。,,Unique函数是一个很有用的工具,可以帮助您快速去除数组中的重复项。在使用它之前,请务必了解其限制和注意事项。
在Python中,unique()函数通常用于去除列表、数组或数据框中的重复项,它可以帮助我们快速地从数据中提取出唯一的元素,下面,我们将详细介绍如何在不同的数据结构中正确使用unique()函数。
列表(List)
在Python列表中,我们可以使用unique()函数来去除重复项,需要注意的是,Python标准库并没有提供unique()函数,我们需要使用第三方库,如numpy或pandas来实现去重功能。
使用numpy
我们需要导入numpy库,可以使用numpy.unique()函数来去除数组中的重复项。
import numpy as np
创建一个包含重复项的数组
arr = np.array([1, 2, 2, 3, 4, 4, 5])
使用unique()函数去除重复项
unique_arr = np.unique(arr)
打印结果
print("Unique elements in the array are:")
print(unique_arr)使用pandas
另一种方法是使用pandas库,我们可以先将数组转换为pandas的Series对象,然后使用unique()方法去除重复项。
import pandas as pd
创建一个包含重复项的数组
arr = [1, 2, 2, 3, 4, 4, 5]
将数组转换为Series对象
series = pd.Series(arr)
使用unique()方法去除重复项
unique_elements = series.unique()
打印结果
print("Unique elements in the array are:")
print(unique_elements)数据框(DataFrame)
在数据框中,我们可以使用unique()函数来去除列中的重复项,这里,我们将使用pandas库来实现。
去除单列中的重复项
我们需要创建一个包含重复项的数据框,可以使用unique()方法来去除列中的重复项。
import pandas as pd
创建一个包含重复项的数据框
df = pd.DataFrame({
'A': [1, 2, 2, 3, 4, 4, 5],
'B': [10, 20, 20, 30, 40, 40, 50]
})
使用unique()方法去除列A中的重复项
unique_elements_A = df['A'].unique()
unique_elements_B = df['B'].unique() # 如果需要,可以同样去除列B中的重复项
打印结果
print("Unique elements in column A are:")
print(unique_elements_A)
print("Unique elements in column B are:") # 如果执行了上述代码,可以打印unique_elements_B的结果去除多列中的重复项(使用reset_index)

有时,我们可能需要去除多列中的重复项,并重置索引,在这种情况下,可以使用reset_index()方法来重置索引,并使用drop=True参数来删除旧的索引列。
import pandas as pd
创建一个包含重复项的数据框
df = pd.DataFrame({
'A': [1, 2, 2, 3, 4, 4, 5],
'B': [10, 20, 20, 30, 40, 40, 50]
})
使用reset_index()方法重置索引并删除旧的索引列
df_reset = df.reset_index(drop=True) # drop=True参数删除旧的索引列(如果有的话)并重置索引为0开始。
unique_elements_A = df_reset['A'].unique() # 现在获取的是重置索引后的数据框中的唯一元素。
unique_elements_B = df_reset['B'].unique() # 如果需要,可以同样获取列B中的唯一元素。 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号